Seeing that the CPU hit the power wall and probably wont go any faster and in the light of the shift to many core machines, software developers are starting to realize that in order to achieve a continuous increase in performances (re-enable the free lunch) there’s no escape from writing programs that scale up to multiple processors, for the most part by introducing more and more parallelism.
In order to make parallel programming easier, Microsoft is introducing a new library called TPL (Task Parallel Library) which aims to lower the cost of fine-grained parallelism by executing the asynchronous work (tasks) in a way that fit the number of available cores, and providing developers with more control over the way in which the tasks get scheduled and executed.
TPL exposes rich set of APIs that enable operations such as waiting for tasks, canceling tasks, optimizing the fairness when scheduling tasks, marking tasks known to be long-running to help the scheduler execute efficiently, creating tasks as attached or detached to the parent task, scheduling continuations that run if a task threw an exception or got cancelled, running tasks synchronously, and more.
Recently, The TPL team published a code base that includes very useful functionality that’s too application-specific to be included in the core of TPL’s Framework. It provides a wealth of code that can be used as a starting point or as a learning tool to understand how various kinds of functionality might be implemented. It’s exposed through the ParallelExtensionsExtras project.
In order to support TPL and to provide a better solution for the increasing number of concurrent tasks, Microsoft made some significant improvements to the CLR ThreadPool for .NET Framework 4.o.
Side by side, Microsoft is making an effort to make effective parallel programming easier by supporting ‘transactional memory’ though the STM.NET platform, which provides experimental language and runtime features that allow programmers to declaratively define regions of code that run in isolation
In this post we’ll discuss the motivation for TPL, examine the improvements made to the CLR ThreadPool and review the operation manner and fundamental features of TPL.
The Free Lunch is Over
Already in the year 2003, CPU performance growth had hit a wall. Up until then, most of us wrote sequential code and relayed on the CPU frequency to consistently raise (in 12 years it climbed from 400Hz to 3.8GHz) while futilely counting on Moore law (that the number of transistors on a chip will double about every two years) to keep on translating into faster processors.
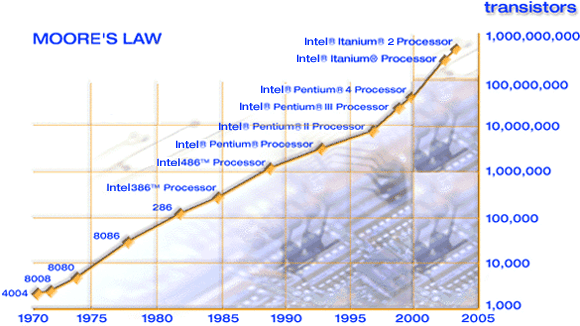
Unfortunately, due to the power wall hit, adding transistors stopped translating into faster processors, primarily because of power consumption and the heat generated.
As you can see in the figure bellow, the number of transistors on Intel’s chips never stopped climbing, even after the year 2010. However, clock speed stopped on 2003 somewhere near 3GHz.
(Source: The Free Lunch Is Over by Herb Sutter)
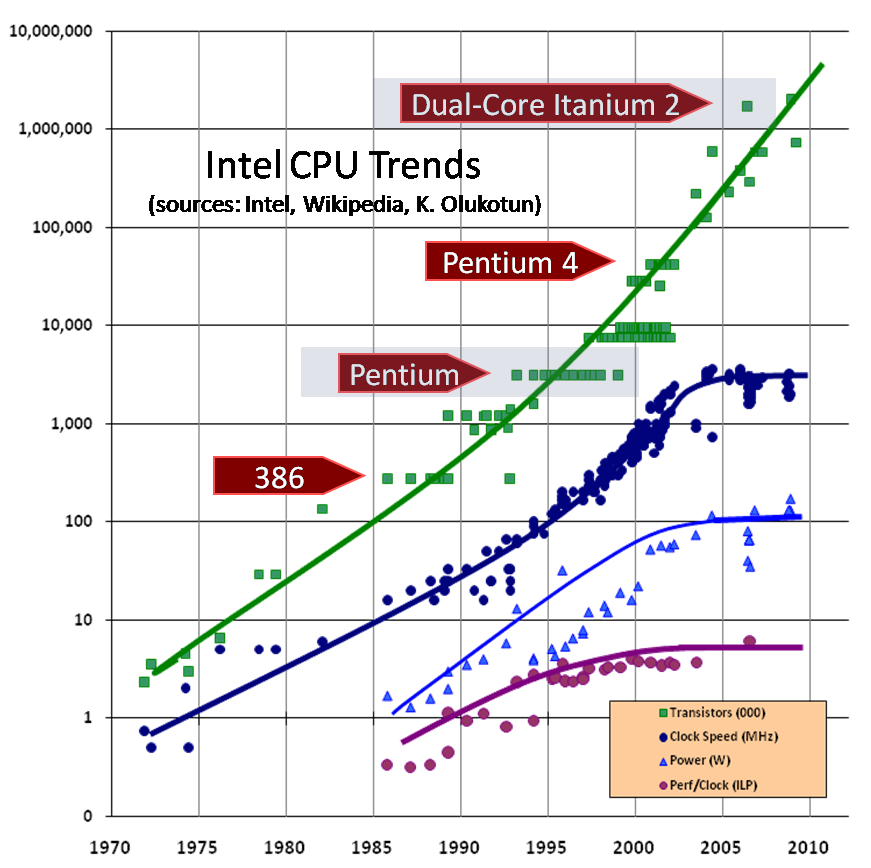
Other CPU vendors are showing similar results..

As a result, instead of putting more and more transistors on a single processor, the major processor manufacturers start putting more and more processors on a single chip.
Intel's Tera-scale Computing Research Program, aimed at breaking barriers to scaling future chips to 10s-100s of cores, has managed to successfully produce a prototype 80-core processor that consumes less than 100W of power, but lacks a lot of necessary functionality.
Recently, Intel has announced that "limited quantities" of an experimental, fully working processors, featuring 48 physical processing cores will be shipping to researchers by the middle of the year. The new processor draws between 25 watts and 125 watts of power, and posses the ability to shutdown cores at will in order to reduce clock speed and power consumption.
Quite possibly, in less than 10 years we will be seeing main stream computers with up to 256 cores!

Legacy versions of windows (XP, Vista, Server 2003) support 32/64 processors on a single machine due to the limitation of the process/thread affinity mask APIs. However, Windows Server 2008 R2 and Windows 7 support up to 256 CPUs.
CLR Thread Pool
The .NET ThreadPool provides a convenient way to run asynchronous work. It optimizes the creation and destruction of threads through the use of heuristic ‘thread injection and retirement algorithm’ that determines the optimal number of threads by looking at the machine architecture, rate of incoming work and current CPU utilization (using daemon thread that runs in the background and periodically monitor the CPU). All in order to reduce the overhead associated with creating and destroying a thread (according to Joe Duffy, it cost approximately 200,000 cycles to create a thread, and 100,000 to destroy one), keep high CPU utilization and minimize the amount of context switches (context switch costs 2,000–8,000 cycles).
How Does the CLR Thread Pool Work?
In the post ‘.NET CLR Thread Pool Internals’ you can find in detail review of the ‘thread injection and retirement algorithm’ which optimizes the creation and destruction of threads in order to execute asynchronous callbacks in a scalable fashion.
CLR Thread Pool 2.0
The CLR 2.0 ThreadPool contains a single queue to which multiple application objects concurrently queue (push) work items and from which multiple worker threads concurrently pull work items. In order to keep things thread safe, an exclusive lock is acquired during the push and during the pull.

Already in .NET Framework 3.5
In order to reduce the number of transitions between AppDomains, since .NET Framework 3.5 the thread pool also maintains separate queue for each AppDomain while using round-robin scheduling algorithms to allow each queue to execute work for some time before moving on to the next.
CLR Thread Pool 4.0
The legacy thread pools was designed for applications that targeted 1-2-4 processors machines. Since applications of that nature usually allow only few worker threads to run coarse grained work concurrently, the ‘single queue’ ‘single lock’ schema worked just fine.
However, new age applications will target machines with hundreds of cores. Consequently, in order to scale up, they’ll have to be designed to run lots of fine grained work concurrently, thus, the number of work items and worker threads will increase dramatically which will result in a problematic contention on the pool.
Performance
The new ThreadPool significantly reduces the synchronization overhead associated with pushing/pulling work items to/from the pool. While in previous versions the ThreadPool queue was implemented as a linked list protected by a big lock - the new version of the queue is based on the new array-style, lock-free, GC-friendly ConcurrentQueue<T> class.
Since the new queue is implemented more like an Array instead of a Linked-List, there’s no need to restructure every time an item is pulled/pushed (which is naturally done within a lock), instead, all that have to be done is to increment/decrement a pointer in an atomic operation via InternalLock. In addition, it’s a lot easier for the GC to travels through an Array than through a Linked-List.
Not official benchmarks published recently show dramatic increase in performance when running on .NET framework 4.0 thread pool. The benchmark runs 10 million empty work items concurrently in order to calculate the thread pool overhead. It provides the following results.
| Machine | .NET 3.5 | .NET 4 | Improvement |
| A dual-core box | 5.03 seconds | 2.45 seconds | 2.05x |
| A quad-core box | 19.39 seconds | 3.42 seconds | 5.67x |
Worker Thread Queues and Work Stealing Support
The CLR 4.0 thread pool also supports a local queue per task and implements a work stealing algorithm that load balance the work amongst the queues. This feature only applies when working with the Task Parallel Library that will be reviewed shortly.
Operation Manner
The ‘thread injection and retirement algorithm’ for CLR 4.0 has changed since previous versions of the CLR, please refer to ‘.NET CLR Thread Pool Internals’ for in detail review.
Backward Compatibility
For most applications the upgrade to the new 4.0 thread pool should be transparent and a performance gain should be spotted without changing line of code. However, the modifications made to the ‘thread injection and retirement algorithm’ require some spatial attention since it might lead to some unaccustomed starvation.
Task Parallel Library
In contrast to working directly with the ThreadPool - Task Parallel Library (TPL) provides rich API for paralleling work. The new API finally enables control over work items (tasks) that were scheduled including non-evil cancelation, it allows the developers to 1) provide more information about the work that is to be scheduled for parallel execution, and 2) configure the scheduling fashion by setting the concurrency level and setting priorities.
The Task Parallel Library includes many features that enable the application to scale better. This post reviews the support for worker thread local pool (to reduce contentions on the global queue) with work stealing capabilities, and the support for concurrency levels tuning (setting the number of tasks that are allowed to run in parallel)
Worker Thread Local Pool
How?
Task task1 = Task.Factory.StartNew(delegate { taskWork(); });
Using the ThreadPool all work requests travel through the same queue and all the worker threads get work items from the same queue. With TPL, in order to reduce the contention on the global queue and to provide better cache behavior - when a parent task schedule tasks, the child tasks don’t get queue in the global queue, rather they’re being queued in a local queue dedicated to the parent task.
When the parent task finishes its own work, the child tasks are picked up and executed by the same thread that executed the parent task. In order to provide a better caching behavior, the child tasks are being fetched from the local pool in a LIFO fashion (the last child that was queued is being fetched first).
When a worker thread is done with all of its work (including executing the child tasks), if there’s no work available in the global queue, it checks other threads local queues to see if there’s any work to steal. If there is, it fetches the work from the other thread local queue in a FIFO fashion.
The local queue is based on an array that changes size dynamically, and has two ends. One end (“private”) allows lock-free pushes and pops, the other end (“public”) requires synchronization. When the queue gets small so private and public operations could conflict, synchronization is necessary.
Child tasks are being fetched from the private end, there for fetching child tasks doesn’t require a lock. Stills are being done from the public end, thus requires the protection of a lock.

The local queuing feature can be disabled by including the PreferFairness flag in the TaskCreationOptions of the parent task (this flag is not included by default); with the PreferFairness flag set – the scheduler will still enqueue the child task to the global queue rather than to the local queue.
Concurrency Control and Priorities
The concurrency control feature enables developers to manually tune the amount of threads (concurrency level) that the TPL task scheduler will ideally generate for a given set of tasks
Please refer to ‘Concurrency Levels Tuning with Task Parallel Library (TPL)’ for code code samples and in detail review.
Benchmark
ThreadPool vs TPL benchmark (for Visual Studio 2008) can be downloaded from here.
Please be very cautious about using this benchmarks to make decisions or to evaluate whether the ThreadPool or TPL is right for you. The implementation and architecture of both have changed significantly since previous releases, and it's quite likely that any performance measurements done thus far are no longer valid. Moreover, in .NET 4.0, the Task Parallel Library uses the new .NET 4.0 ThreadPool as its default scheduler
ThreadPool vs TPL benchmark (for Visual Studio 2010 beta) can be downloaded from here.
Links
Parallel Programming with .NET : Slides from Parallelism Tour
CLR Inside Out - Using concurrency for scalability (Joe Dufy)
CLR Inside Out - Thread Management In The CLR
Sasha's articles about parallelism
Video - Daniel Moth presents working with ThreadPool v.s. TPL, TaskMananger and Task cancelation
http://blogs.msdn.com/ericeil/archive/2009/04/23/clr-4-0-threadpool-improvements-part-1.aspx
http://blogs.msdn.com/salvapatuel/archive/2007/11/11/task-parallel-library-explored.aspx
http://www.danielmoth.com/Blog/2008/11/new-and-improved-clr-4-thread-pool.html
No comments:
Post a Comment